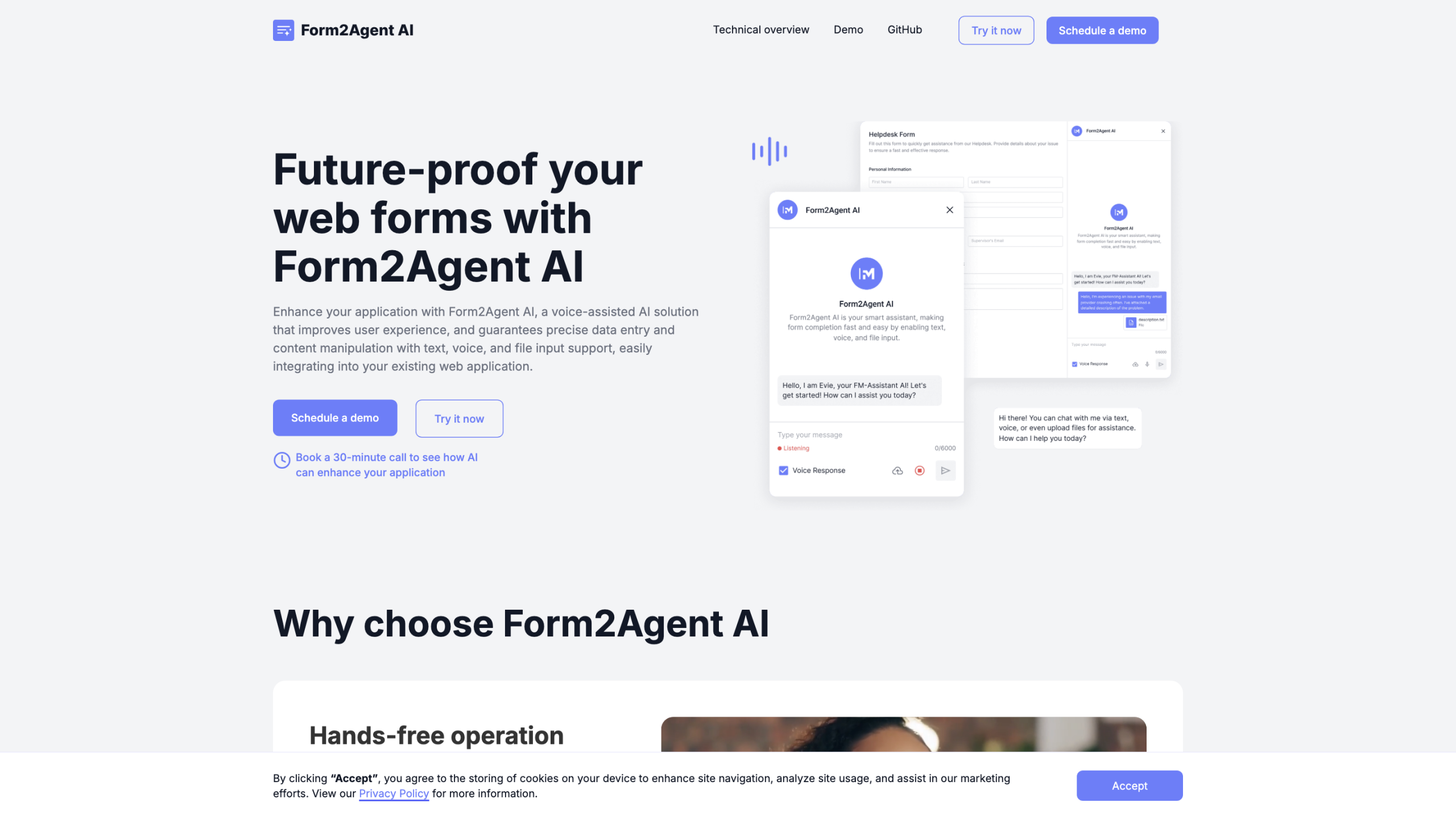
ChatTTS: текстовая речь для чата это модель генерации голоса, оптимизированная для разговорных сценариев, предназначенная для обеспечения естественной, плавной речи для задач диалога, типичных для помощников большой языковой модели (LLM) и приложений, таких как разговорные аудио и видео введения. Он поддерживает английский и китайский языки и обучается на большом, разнообразном наборе данных для обеспечения высококачественной, естественно звучащей речи. Проект подчеркивает простоту использования, многоязычную поддержку и потенциальную открытость через исходные линии с открытым исходным кодом.
Как работает ChatTTS
- Многоязычная поддержка (английский и китайский) позволяет использовать различные аудитории.
- Обучался примерно 100 000 часов китайским и английским данным для достижения естественного качества речи.
- Подходит для задач диалога, обеспечивая согласованные, контекстно-осознанные голосовые ответы в разговорах.
- Планирует открыть исходный код базовой модели, обученной на 40 000 часов данных для содействия исследованиям и сотрудничеству.
- Сосредоточьтесь на управляемости, включая водяные знаки и интеграцию с LLM для безопасной и надежной работы.
- Простой ввод: только текст, который преобразуется в файлы речи.
Как использовать ChatTTS
- Скачать из GitHub: Clone the Repository (пример: git Clone) https://github.com/2noise/ChatTTS).
- Установите зависимости (например, факел и ChatTTS через pip).
- Импорт необходимых библиотек (факел, ChatTTS и Audio с IPython.display).
- Инициируйте ChatTTS и загружайте предварительно обученные модели.
- Подготовьте свой текстовый ввод(ы).
- Генерировать речь с помощью метода вывода (возможно включить опцию Use decoder).
- Воспроизведение или сохранение сгенерированного аудио с использованием стандартных инструментов воспроизведения аудио.
- Справочный пример сценария, представленный в проекте для быстрой настройки.
Случаи использования
- Разговорные задания для ассистентов LLM.
- Создание диалоговой речи для видеозаписей или образовательного контента.
- Любое приложение, требующее естественного, динамического синтеза речи на китайском или английском языках.
- Потенциальная интеграция в веб-, мобильные, настольные или встроенные среды через предоставленные SDK/API.
Язык и детали данных
- Языки: английский и китайский.
- Данные об обучении: ~ 100 000 часов китайской и английской речи.
- Планы с открытым исходным кодом: базовая модель обучила около 40 000 часов данных, запланированных для выпуска исследователям и разработчикам.
Безопасность, кастомизация и расширяемость
- Открыт для настройки с помощью тонкой настройки с пользовательскими наборами данных для конкретных голосов или доменов.
- Улучшения управляемости, включая водяные знаки, для повышения безопасности и прослеживаемости при развертывании с LLM.
- Базовые условия с открытым исходным кодом позволяют сообществу экспериментировать и совершенствоваться.
Основные характеристики
- Многоязычный (английский и китайский) синтез голоса, адаптированный для разговорных задач
- Качественная, естественно звучащая речь благодаря масштабным данным обучения (~100 тыс. часов)
- Стратегия с открытым исходным кодом с планами выпуска базовой модели, обученной на ~40 тыс. часов
- Легкая интеграция в приложения и разговорные системы на базе LLM
- Функции управляемости и потенциальные водяные знаки для более безопасного развертывания
- Простой рабочий процесс от текста к речи: ввод текста, генерация аудио и воспроизведение / сохранение
- Межэкологическая совместимость (веб, мобильный, настольный, встроенный) через SDK/API