Обработка больших данных для эпохи ИИ — LakeSail
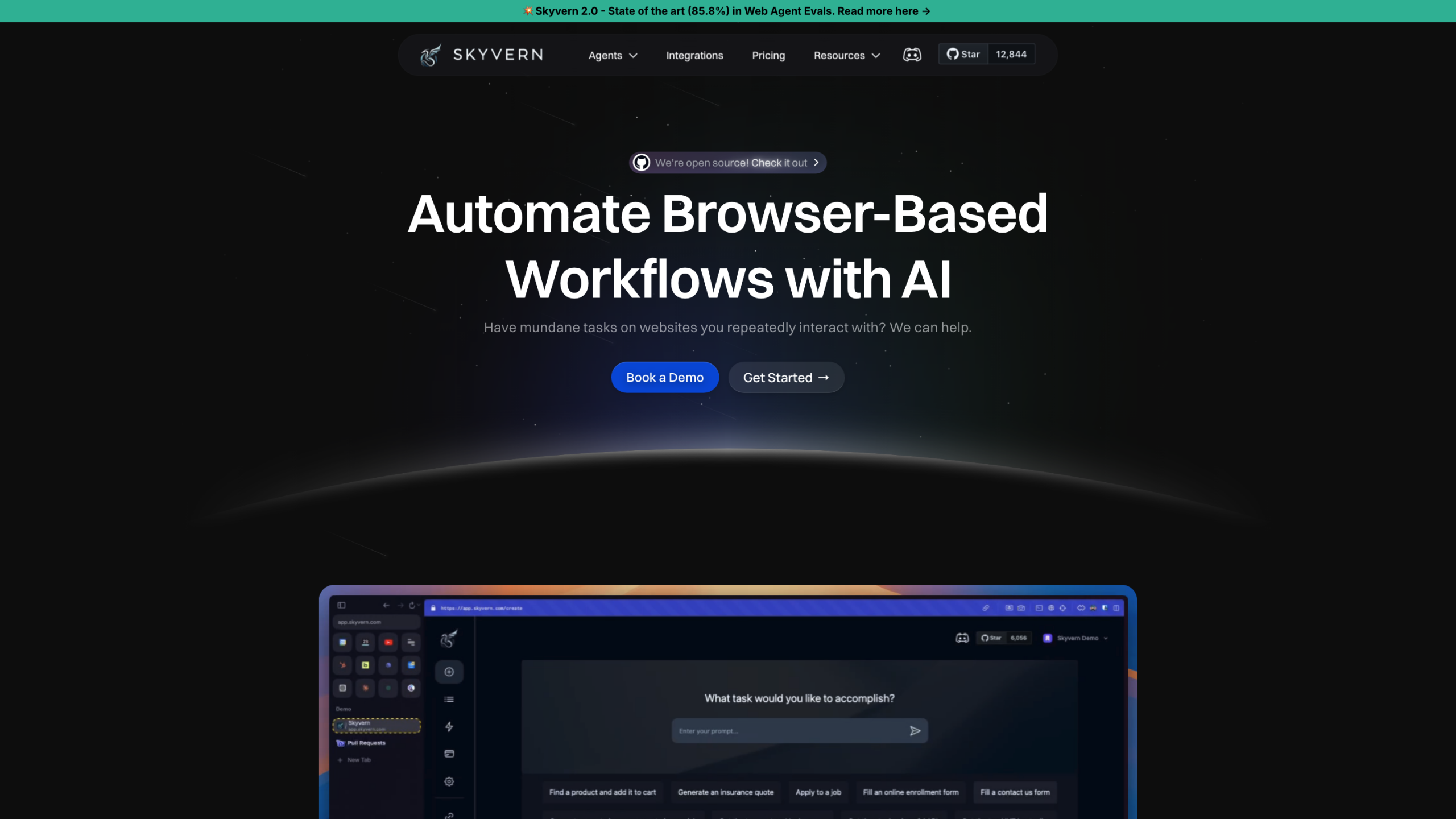
LakeSail — это вычислительная среда с открытым исходным кодом, предназначенная для унификации пакетной обработки, потоковой обработки и вычислительно-интенсивных рабочих нагрузок ИИ. Он обеспечивает замену Apache Spark SQL и Spark DataFrame API как в однохостовой, так и в распределенной среде, обеспечивая быструю и эффективную обработку данных с минимальными изменениями кода.
Обзор
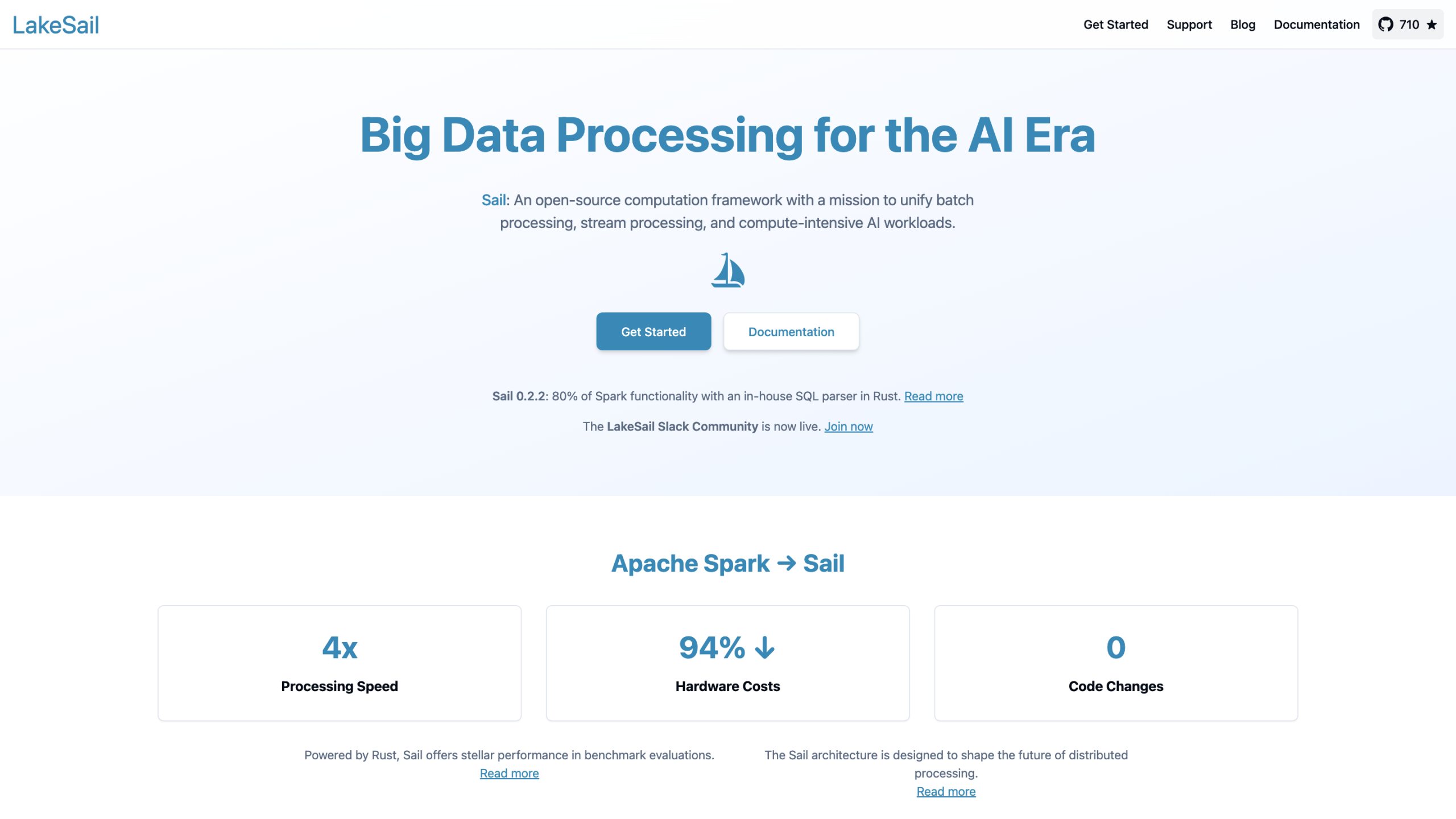
- LakeSail (Sail) стремится ускорить задачи обработки данных, одновременно снижая затраты на оборудование и сохраняя простоту использования. Он достигает 4-кратного улучшения скорости обработки и 0 дополнительных изменений кода в тест-оценках, основанных на собственном SQL-парсере и архитектуре, предназначенной для оптимизации производительности.
- Sail предлагает совместимость с Spark SQL и Spark DataFrame API, позволяя пользователям запускать существующие рабочие процессы Spark с минимальными нарушениями.
- Он предоставляет инструменты и руководство для запуска, включая команды установки, настройку сервера и примеры подключения PySpark к движку SQL, поддерживаемому Sail.
Начинай
- Варианты установки включают в себя пакет Python: Pip установите «pysail[spark]» вместе с инструментами командной строки для Sail.
- Запустите сервер Sail локально или в кластере (например, Kubernetes) и подключитесь к нему из PySpark без изменения существующего кода PySpark.
Пример сниппетов настройки:
- Установка CLI и запуск сервера
- баш
- pip install «pysail[spark]»
- парусный искровой сервер, порт 50051
- Подключение PySpark к Sail
- питон
- from pyspark.sql import SparkSession
- spark = SparkSession.builder.remote(«sc://localhost:50051»).getOrCreate()
- spark.sql(«SELECT 1 + 1»).show()
- Развертывание Kubernetes
- баш
- kubectl apply -f sail.yaml
- kubectl -n парусный порт-форвард/парус-искра-сервер 50051:50051
Архитектура и возможности
- Sail предназначен для формирования будущего распределенной обработки данных с акцентом на производительность, масштабируемость и простоту интеграции.
- Он обеспечивает замену Spark SQL и API DataFrame, позволяя беспрепятственно перемещаться из рабочих нагрузок на основе Spark.
- Архитектура поддерживает как однохостовые, так и распределенные модели развертывания.
Особенности
- Drop-in replacement for Spark SQL and Spark DataFrame API
- Высокая производительность при анализе и оптимизации SQL на основе Rust
- Совместимость с PySpark без изменений кода
- Поддерживает как пакетные, так и потоковые рабочие нагрузки (унифицированная обработка)
- Варианты развертывания Kubernetes для масштабируемых сред
- Инструменты PyPI и CLI для простой установки и эксплуатации
- Варианты коммерческой поддержки с гибким покрытием
Как это работает
- Установите Sail и запустите сервер Sail.
- Подключите существующий код PySpark к серверу Sail, используя URL-адрес sc://localhost:50051.
- Выполняйте операции SQL и DataFrame; Sail обрабатывает планирование выполнения и распределенные вычисления под капотом.
Поддержка и сообщество
- LakeSail предлагает коммерческую поддержку с различными вариантами, адаптированными к потребностям пользователей.
- Ресурсы сообщества включают в себя общественный трекер и публичный канал Slack; корпоративные планы обеспечивают частное отслеживание проблем и выделенные каналы с гарантированным временем отклика.
Безопасность и правовые соображения
- Используйте Sail в соответствии с его лицензией и условиями обслуживания. См. официальную документацию по передовой практике развертывания, конфигурациям безопасности и управлению данными.
Основная информация
- Оригинальное название: Sail (LakeSail)
- Цель: Унифицировать пакетные, потоковые и рабочие нагрузки ИИ с совместимым с Spark интерфейсом
- Язык и время выполнения: ядро на основе Rust; интеграция с Python (PySpark)
- Развертывание: одноместное или распределенное; поддержка Kubernetes
- Лицензирование: Открытый исходный код с вариантами коммерческой поддержки