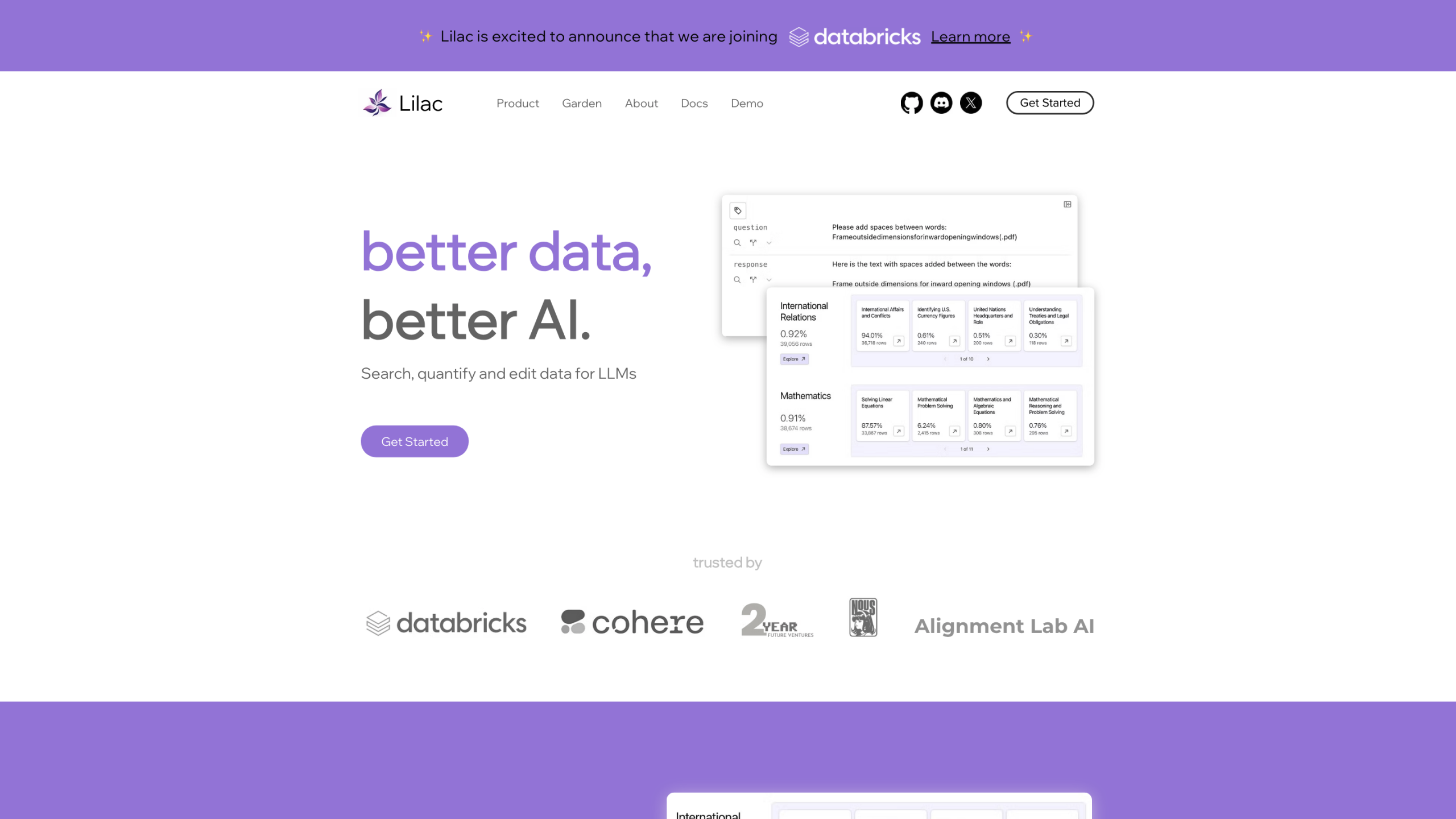
Lilac: лучшие данные, лучший ИИ это платформа данных, предназначенная для поиска, количественной оценки и редактирования данных для LLM. Он обеспечивает быстрые вычисления набора данных, семантический и поиск по ключевым словам, PII и обнаружение дубликатов, обнаружение языка, пользовательские сигналы и поиск с нечеткой концепцией с уточнением. Lilac делает акцент на быстрой обработке данных, высококачественном отборе данных и демократизированном обмене данными между организациями.
Обзор
- Lilac предоставляет инструменты для поиска, количественной оценки и редактирования наборов данных, используемых для больших языковых моделей (LLM).
- Он предлагает кластеризацию, встраивание наборов данных с высокой пропускной способностью и быстрые преобразования данных для ускорения конвейеров подготовки данных.
- Платформе доверяют команды для оценки качества данных, понимания наборов данных и выбора данных для конкретных задач.
Как использовать Lilac
- Установите пакет Python.
pip install lilac - Доступ к пользовательскому интерфейсу Python. Используйте предоставленный пользовательский интерфейс для взаимодействия с вашими наборами данных.
- Начните быстро. Следуйте направляемым рабочим процессам для поиска, кластеризации и уточнения данных для задач LLM.
Ключевые способности
- Поиск и количественная оценка данных для LLM
- Семантический и поиск по ключевым словам для точного поиска данных
- Редактировать и сравнивать поля для согласования различий в наборах данных
- Обнаружить PII, дубликаты, язык или пользовательские сигналы
- Поиск с нечеткой концепцией с уточнением для поиска нюансов данных
- Блестяще быстрые вычисления набора данных: кластер и название 1 миллион точек данных за 20 минут
- Высокопроизводительные встраивания: встраивайте свой набор данных в полмиллиарда токенов в минуту
- Ускоряйте собственные преобразования данных с помощью масштабируемой обработки
- Быстрое начало демонстраций и документации для бортовых команд быстро
Случаи использования
- Трубопроводы оценки качества данных
- Понимание набора данных и обнаружение темы
- Выбор правильных данных для данной задачи ИИ
- Демократизация наборов данных по всей организации для более широкого сотрудничества
Отзывы
- Джонатан Та Лми, Руководитель отдела сбора данных: «Сирень является невероятно мощным инструментом для исследования данных и контроля качества. Мы ежедневно используем Lilac для проверки и оценки наборов данных, а затем демократизируем их по всей организации. Это важнейшая часть нашего процесса оценки качества данных»
- Джонатан Франкл, главный специалист по нейронным сетям: «Lilac обеспечивает простой путь к пониманию концепций в наборах данных и выбору правильных данных для задачи»
- Соучредитель NousResearch Teknium: «Каждый, кто работает с наборами данных LLM, должен ознакомиться с платформой данных @lilac ai… Их кластеризация помогла определить многие темы, которые сегодня освещает Гермес-2.5»
Как это работает
- Установите и настройте Lilac в своей среде.
- Загрузите свои наборы данных и запустите семантический поиск / поиск по ключевым словам, чтобы найти соответствующие точки данных.
- Используйте кластеризацию и встраивание для организации и сравнения данных в масштабе.
- Применяйте изменения и сигналы для уточнения вашего набора данных, улучшая производительность LLM.
Безопасность и правовые соображения
- Обеспечить надлежащую обработку конфиденциальных данных (PII) и соблюдать политику управления данными вашей организации при использовании Lilac.
Основные характеристики
- Начать: быстрая установка и посадка на борт для быстрой ценности
- Поиск, количественная оценка и редактирование данных для LLM: сквозной рабочий процесс подготовки данных
- Semantic & Keyword Search: Гибкий поиск по большим наборам данных
- Edit & Compare Fields: Согласование и гармонизация атрибутов данных
- PII, дубликаты, обнаружение языка или пользовательский сигнал: надежные проверки качества данных
- Поиск с нечеткой концепцией с уточнением: нюансы обнаружения данных
- Блестяще быстрые вычисления наборов данных: кластер и заголовок 1М точек данных за 20 минут
- Встраивание пропускной способности: полмиллиарда токенов в минуту
- Ускоренные преобразования данных: масштабируемые конвейеры обработки данных
- Интеграция Python: простая установка pip и Python UI для разработчиков
Начало работы
- Установить:
pip install lilac - Запуск: Получите доступ к интерфейсу Python и начните изучать наборы данных
- Узнайте больше: Изучите документы и демонстрации, чтобы максимизировать качество данных и выбор данных для конкретных задач