Обсуждение:LLM Web Scrape
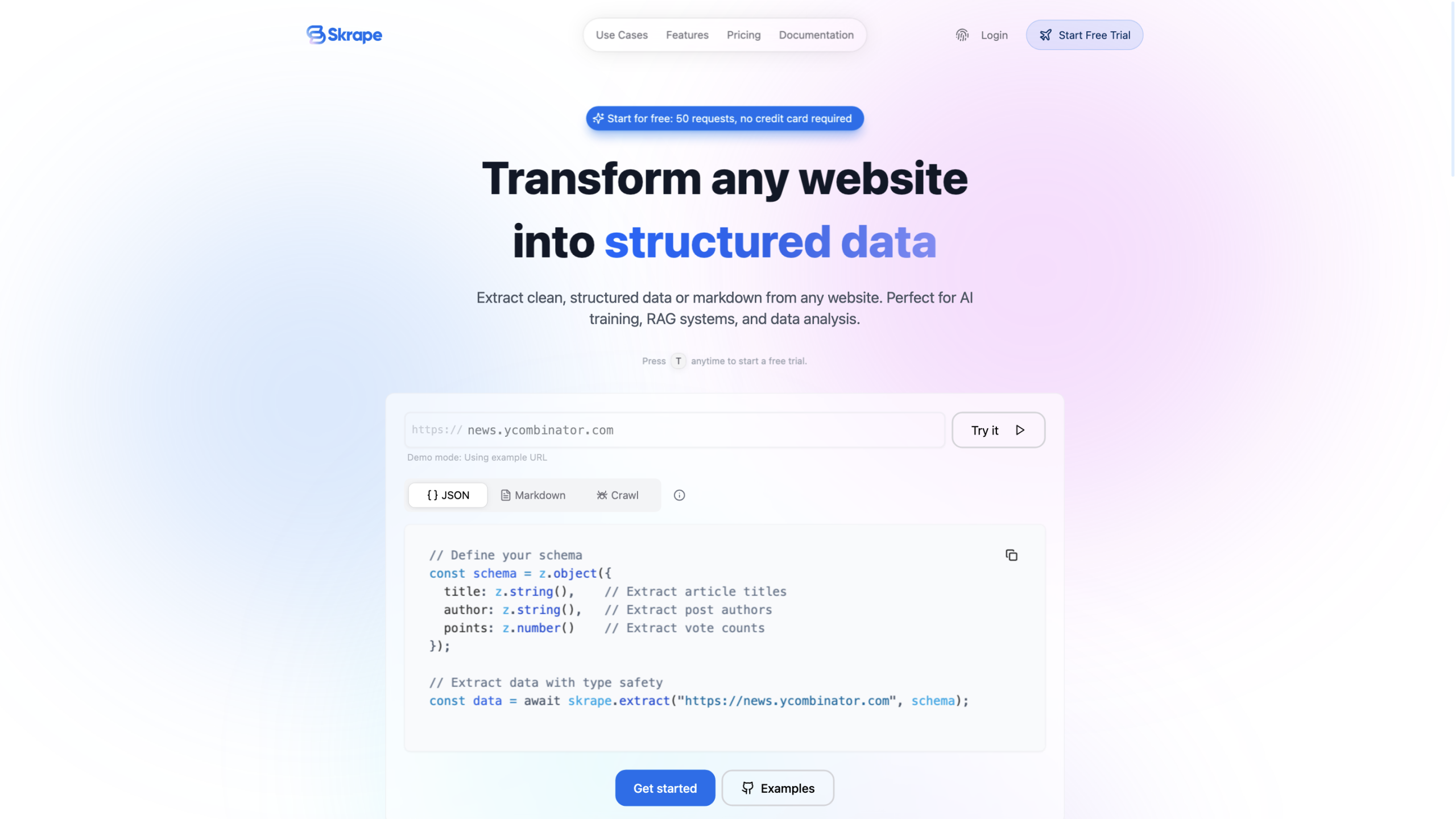
Skrape — это платформа веб-скребинга с поддержкой LLM, которая преобразует любой веб-сайт в чистые структурированные данные. Он поддерживает автоматическое извлечение данных, обновления контента в реальном времени и дружественные к разметке результаты, что делает его идеальным для обучения ИИ, систем RAG, анализа данных и построения базы знаний. Инструмент подчеркивает простоту использования, надежность и масштабируемость конвейеров данных.
Ключевые случаи использования
- Сбор данных, готовых к RAG: преобразуйте веб-сайты в чистые структурированные наборы данных для генерации с расширенным поиском
- Трубопроводы данных обучения: автоматизированный сбор доменного, многоязычного контента и структурированных примеров обучения
- Создание базы знаний: агрегированный многоисточниковый веб-контент для расширенного контекста ИИ
- Мониторинг контента ИИ: отслеживайте новости, связанные с ИИ, исследовательские документы и техническую документацию
- Данные оценки моделей: сбор разнообразных реальных данных для бенчмаркинга производительности LLM
- Документация и ссылки на API: скребок и структура API документы, технические руководства и примеры кода
Как это работает
- Умное покрытиеАвтоматически сканирует веб-сайты (даже без карт сайта), уважая robots.txt.
- Динамическая обработка контентаПолная поддержка JavaScript для SPA и динамической загрузки контента.
- Чистый результат MarkdownВозвращает данные в хорошо отформатированной разметке, подходящей для немедленного использования.
- Пользовательская схема и экстракцияОпределение схем для извлечения структурированных данных точно по мере необходимости.
- Данные в реальном времениВсегда извлекает свежие данные, избегая кэшированных результатов.
Особенности
- Smart Crawling: автоматическое прохождение сайта с уважением к роботам. txt
- Динамический контент: полная поддержка JavaScript для SPA
- Clean Markdown Output: готовые к использованию отформатированные данные
- Экстракция на основе схемы: определите схему данных для структурированных результатов
- Получение данных в режиме реального времени: нет устаревших данных, обновленный контент
- API & Documentation Scraping: структурированное извлечение из технических документов и ссылок на API
- Поддержка нескольких языков: сбор контента на разных языках
- RetrievaI-Augmented Data: бесшовная интеграция с рабочими процессами RAG
- No-Coding Workflow: удобные интерфейсы для быстрой настройки
- Масштабируемые уровни цен: от бесплатных испытаний до корпоративного использования
Как использовать Skrape
- Начните с бесплатной пробной версии, чтобы изучить 50 кредитов и начать соскоб.
- Настройте целевые URL-адреса и определите схему извлечения (поля, селекторы или шаблоны).
- Запустите сканирование для сбора контента, отображения динамических страниц и вывода в виде Markdown.
- Экспорт структурированных данных для обучения ИИ, аналитики или баз знаний.
Цены и планы
- Бесплатный уровень: 50 кредитов / не требуется кредитная карта
- Стартер: $15/месяц – до 3000 страниц и 3000 кредитов, 10 запросов за 10 секунд
- Рост: 50 долларов в месяц — до 10 000 страниц и 10 000 кредитов, 20 запросов за 10 секунд
- Pro: 250 долларов в месяц — до 50 000 страниц и 50 000 кредитов, 30 запросов за 10 секунд
- Пользователь: индивидуальные тарифные лимиты и квоты для больших команд
Все планы включают доступ к API, документацию и поддержку.
Готовы преобразовать данные?
Начните со Skrape и преобразуйте любой веб-сайт в чистые структурированные данные, подходящие для обучения ИИ, RAG и анализа данных. Начните бесплатно и масштабируйте по мере необходимости.
Связанные ресурсы
- API Документация
- Учебные коллекции
- База знаний и мониторинг блогов
- FAQ и поддержка