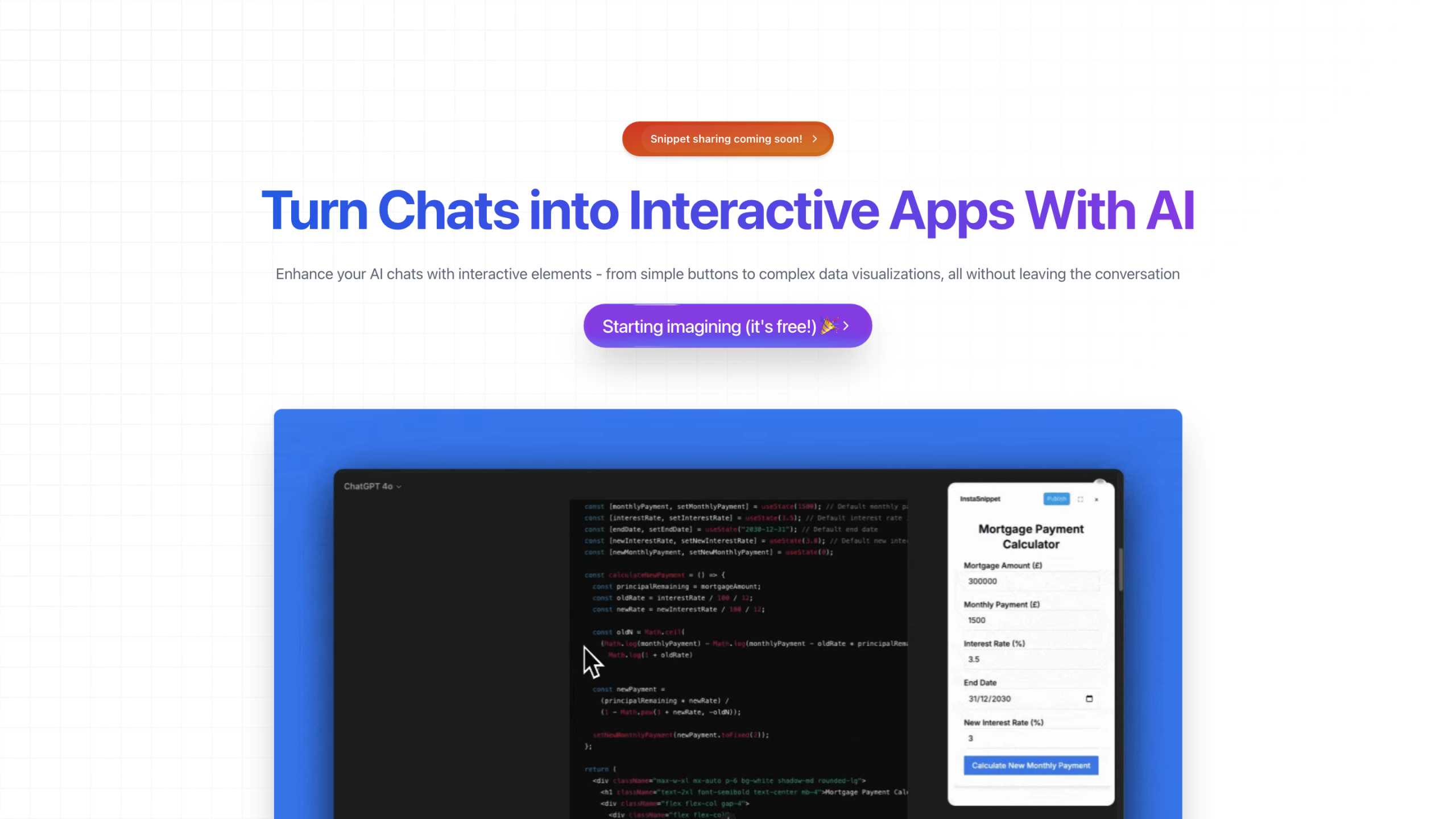
Spice AI – Open Source Data & AI Inference Engine
Spice AI — это механизм вывода данных и ИИ с открытым исходным кодом, предназначенный для того, чтобы помочь разработчикам создавать приложения на базе ИИ, основанные на корпоративных данных. Он обеспечивает федерацию запросов SQL, ускорение данных, поиск и поиск, интегрируя модели ИИ и данные из современных и устаревших источников. Платформа подчеркивает скорость, масштабируемость и удобный для разработчиков опыт, с акцентом на развертывание возможностей ИИ вблизи источников данных и в готовых к производству средах.
К ключевым возможностям относятся:
- Федерация SQL Query: Присоединяйтесь к данным в базах данных, хранилищах данных, озерах данных и API, используя знакомый синтаксис SQL в одном запросе.
- Ускорение данных: быстрый запрос с низкой задержкой, поиск и поиск ИИ с производительностью в реальном времени или почти в реальном времени.
- AI Inference & Training: Загрузите локальные модели (например, Llama3) или подключитесь к размещенным службам ИИ (OpenAI, xAI, NVidia) и запустите рабочие нагрузки ML / AI.
- Compute Engine: портативный высокопроизводительный вычислительный движок на основе Rust, построенный на Apache Arrow и DataFusion для эффективной обработки в памяти.
- Блоки построения: Композитные компоненты для доступа к данным, ускорения, поиска, поиска и вывода ИИ, которые могут быть сшиты вместе для питания приложений и агентов, основанных на данных.
- Коннекторы: 30+ разъемов к источникам из Databricks, MySQL, CSV на FTP и многое другое, со стандартными протоколами (ODBC, JDBC, ADBC, HTTP, Apache Arrow Flight).
- Real-Time & CDC: поддержка сбора данных об изменениях (CDC) для поддержания ускорений и индексов в актуальном состоянии.
- Минимальные требования к настройке и коду (три строки кода для запуска в Spice Cloud Platform) с надежными SDK.
- Ecosystem & SDKs: Node.js, Python, Go, Rust, с дополнительными SDK и экосистемными библиотеками (Pandas, PyTorch, TensorFlow и др.).
- Инфраструктура корпоративного уровня с опциями SOC 2 Type II для безопасной обработки данных и управления ими.
- Data & AI Store: поддержка таких материалов, как DuckDB, SQLite и частные наборы данных / просмотры для SQL-запроса и совместного использования.
- Частные и публичные развертывания: Гибкие варианты развертывания для облачных, локальных или гибридных сред.
Основные преимущества включают быстрый доступ к данным в реальном времени, интегрированные возможности ИИ и модульную архитектуру, которая позволяет командам быстро создавать приложения и агенты ИИ, основанные на реальных корпоративных данных.
Как работает Spice AI
- Запрос по различным источникам данных с помощью SQL, используя федерацию данных для соединения наборов данных в одном запросе.
- Используйте встроенный вычислительный движок для выполнения ИИ-интенсивных рабочих нагрузок, близких к данным, поддерживаемых локальными или размещенными моделями.
- Применяйте ускорение данных и поиск ИИ для быстрой, интерактивной работы и приложений с поддержкой ИИ.
- Оркестровый доступ к данным, ускорение, поиск, поиск и вывод ИИ с помощью композитных строительных блоков для создания приложений и агентов.
Основные характеристики
- Данные с открытым исходным кодом и механизм вывода AI
- Федерация SQL Query по базам данных, складам, озерам и API
- Ускорение данных для быстрых запросов с низкой задержкой и поиска ИИ
- Загрузить и обслуживать локальные модели ИИ (например, Llama3) или размещенные платформы (OpenAI, xAI, NVidia)
- Рустовой вычислительный движок на Apache Arrow/DataFusion для производительности
- Строительные блоки, которые могут быть составлены для создания основанных на данных приложений и агентов ИИ
- 30+ разъемов для современных и устаревших источников (Databricks, MySQL, CSV / FTP и т. Д.)
- Стандартные протоколы: ODBC, JDBC, ADBC, HTTP, Arrow Flight (gRPC)
- Захват данных об изменениях (CDC) для обновления ускорений в режиме реального времени
- Трехлинейный код в Spice Cloud Platform
- SDK через Node.js, Python, Go, Rust; взаимодействие с Pandas, PyTorch, TensorFlow
- Частные наборы данных и просмотры, доступные через SQL; дополнительный обмен
- Доступ к данным петабайтного масштаба для приложений и случаев использования ML
- Инфраструктура корпоративного уровня с вариантами соответствия SOC 2 типа
Как начать работу
- Начните с трех строк кода: запросите данные и быстро запустите рабочие нагрузки ИИ через платформу Spice Cloud.
- Зарегистрируйтесь для доступа к полному планетарному SQL-запросу и возможностям ML или используйте автономные компоненты с открытым исходным кодом.
- Изучите примеры и библиотеки экосистем для ускорения развития.
Безопасность, конфиденциальность и соблюдение
- Функции безопасности и управления корпоративного уровня с опциями SOC 2 Type II.
- Данные хранятся в контролируемых средах в соответствии с выбором развертывания и организационной политикой.
Связанные ресурсы
- Оригинальное название: Get Started, Read the Docs
- Тематические исследования: реальные развертывания и варианты использования
- Сообщество и учебные пособия: Примеры библиотек и вклад сообщества
Основные характеристики Summary
- Открытые исходные данные и AI Inference Engine
- Федерация SQL Query в источниках данных
- Ускорение данных с быстрой обработкой в памяти
- Поддержка локальных и хостинговых моделей ИИ
- Rust-based, Arrow/DataFusion-powered Compute Engine
- Композитные строительные блоки для данных и приложений ИИ
- 30+ Data Source Connectors со стандартными протоколами
- Индексация данных в реальном времени с CDC
- Трехлинейный код в Spice Cloud Platform
- Богатые SDK (Node.js, Python, Go, Rust) и экосистемная совместимость
- Частные наборы данных, просмотры и доступ на основе SQL
- Корпоративные варианты SOC 2