WaterCrawl — современная система веб-кралинга
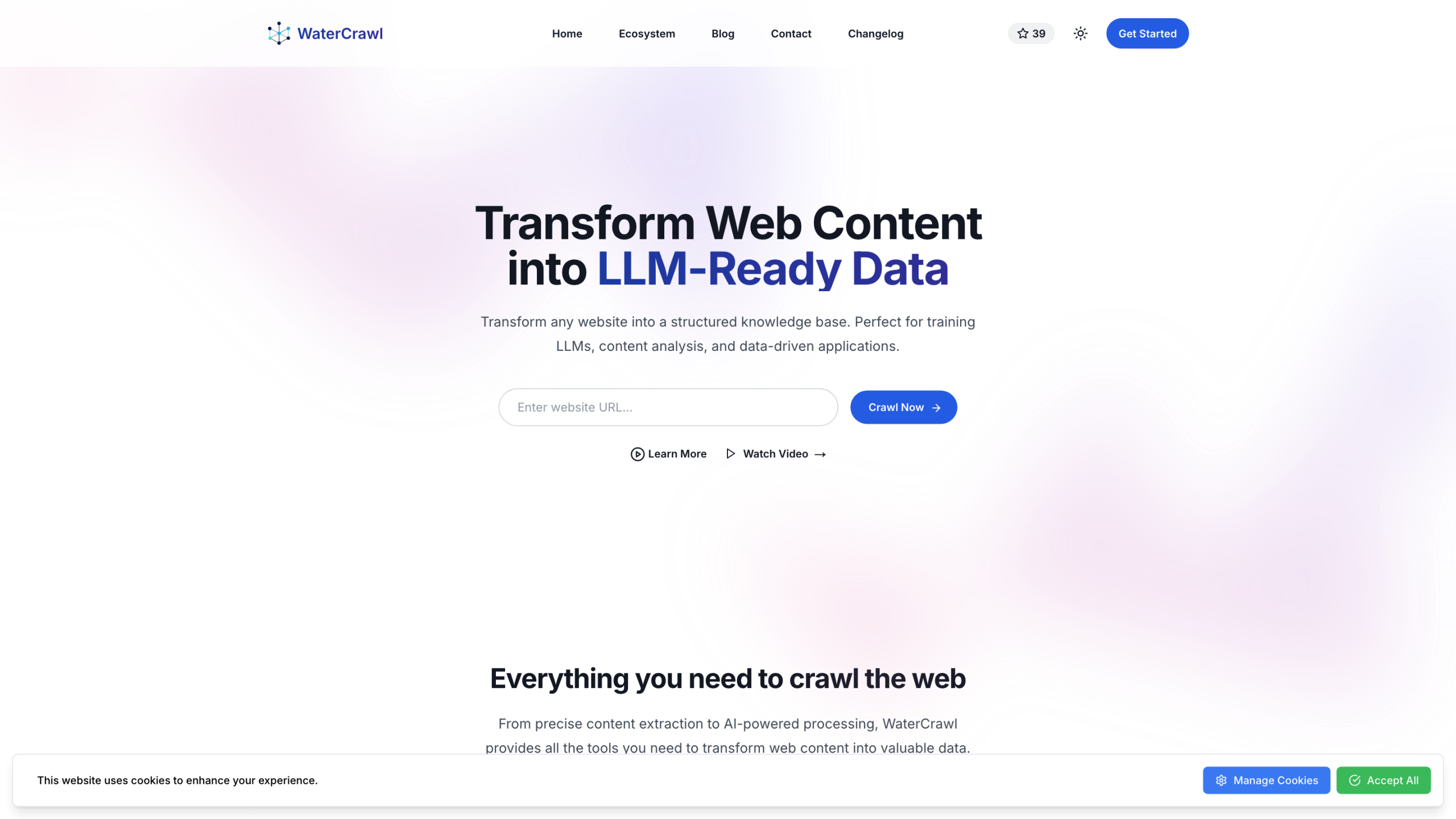
WaterCrawl — это всеобъемлющая структура веб-сканирования, предназначенная для преобразования любого веб-сайта в структурированную базу знаний, позволяющую извлекать, анализировать и обрабатывать данные, удобные для ИИ. Он сочетает в себе точное извлечение контента, обработку на основе ИИ и расширяемую поддержку плагинов, чтобы помочь пользователям создавать приложения, основанные на данных, обучать LLM и эффективно анализировать веб-контент. Платформа подчеркивает прозрачность, принципы с открытым исходным кодом и легкую интеграцию с существующими стеками через SDK.
Ключевые способности
- Точное извлечение контента: Сосредоточьтесь на основном контенте с помощью настраиваемых селекторов для фильтрации рекламы, нижних колонтитулов и шума.
- Встроенная интеграция OpenAI для автоматического преобразования исходного HTML в структурированные, значимые данные.
- Расширяемая система плагинов: Создание и интеграция пользовательских плагинов для адаптации функциональности к конкретным вариантам использования.
- Рендеринг JavaScript: Динамический контент с настраиваемым временем ожидания и опциями рендеринга; получение результатов в виде скриншотов PDF или JPG.
- Свобода открытого исходного кода: Прозрачная, совместная архитектура, поощряющая настройку и вклад.
- Интерфейс игровой площадки: интерактивная среда для тестирования селекторов и экстракторов перед развертыванием.
- Доступные SDK для Python, PHP, Node.js, Rust и Go для упрощения интеграции с различными техническими стеками.
Как это работает
- Определите область сканирования с расширенными элементами управления (глубина, домены, пути).
- Используйте точные селекторы для извлечения желаемого контента с целевых веб-страниц.
- Используйте обработку на основе ИИ для преобразования извлеченного контента в структурированные данные.
- Расширяйте функциональность с помощью плагинов и отображайте динамический контент при необходимости.
- Разверните свой стек с помощью SDK и интегрируйте его в свои конвейеры данных или рабочие процессы обучения LLM.
Основные характеристики
- Точное извлечение контента с помощью настраиваемых селекторов
- Обработка на основе ИИ для автоматической структуры данных
- Расширяемая система плагинов для пользовательских функций
- JavaScript-рендеринг для динамических страниц с настраиваемым временем ожидания
- Снимок экрана в форматах PDF или JPG
- Открытый исходный код с прозрачным вкладом в развитие и сообщество
- Интерактивная игровая площадка для тестирования селекторов и экстракторов
- Многоязычные SDK (Python, PHP, Node.js, Rust, Go) для простой интеграции
Как начать работу
- Исследуйте игровую площадку для тестирования селекторов и экстракторов.
- Используйте SDK для интеграции WaterCrawl в конвейер данных вашего проекта.
- Настройка области сканирования, селекторов и обработки ИИ для преобразования веб-контента в структурированные данные, готовые для обучения или анализа LLM.
Безопасность и правовые соображения
- Уважать авторские права и условия обслуживания целевых веб-сайтов.
- Использование для законного извлечения данных, анализа контента и подготовки генерации данных.
Быстрая ссылка
- Превратите любой сайт в структурированную базу знаний.
- Обработка контента на основе ИИ с интеграцией OpenAI.
- Open Source с настраиваемыми плагинами и SDK.