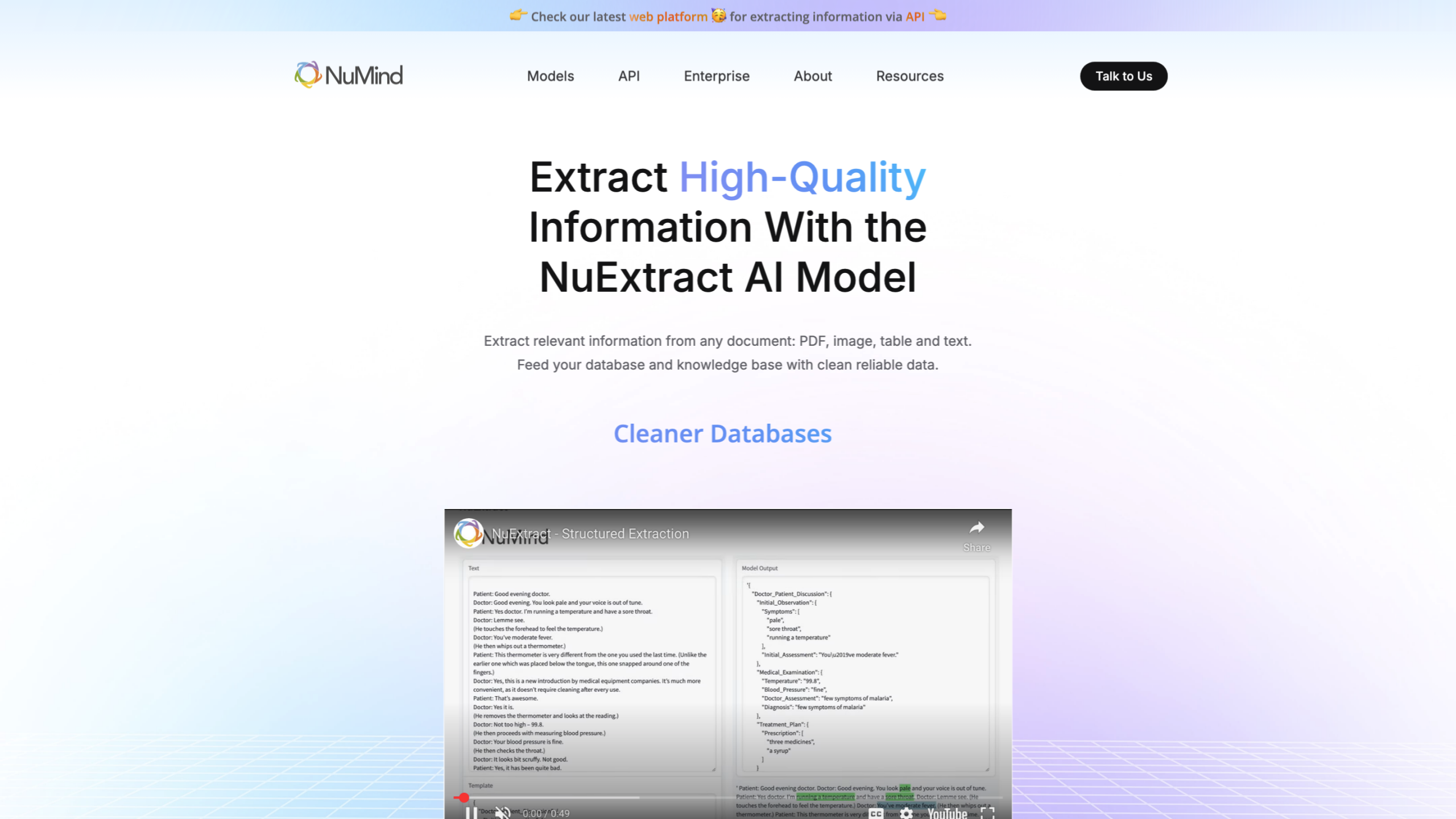
NuMind: решайте задачи по извлечению информации это платформа на базе искусственного интеллекта, предназначенная для извлечения высококачественной структурированной информации из различных документов (PDF, изображений, таблиц и текста). Он предлагает API для масштабируемой экстракции, локальную опцию Enterprise для развертывания, ориентированного на конфиденциальность, и специализированные модели, настроенные для уменьшения галлюцинаций и повышения точности в задачах извлечения информации. Платформа предназначена для профессионалов, которым нужны чистые данные для подачи баз данных и баз знаний, а также поддерживает пользовательские рабочие процессы через автономные агенты и персонализированные конфигурации.
Как работает NuMind
- Извлечение высококачественной информацииИспользуйте NuExtract, флагман LLM, для интеллектуального извлечения структурированных данных из документов. Создайте ключ API и масштабируйте извлечения через API.
- Качество Enterprise-GradeNuMind подчеркивает данные корпоративного качества с моделями, обученными минимизировать галлюцинации, настраиваемыми для конкретных областей и рабочих процессов.
- Предварительное развертываниеДля критически важных для конфиденциальности сред развертывайте настраиваемые модели ИИ на местах, чтобы всегда сохранять конфиденциальность данных.
- Автономные агентыСоздавайте автономные агенты, которые изучают ваш рабочий процесс и выполняют действия, автоматически предоставляя отформатированный контент.
Как использовать NuMind
- API-платформа доступаЕсли у вас есть технический опыт и вы хотите интегрировать извлечение в свои системы, зарегистрируйтесь, создайте ключ API и начните извлекать структурированную информацию из документов в масштабе.
- Предварительное развертываниеДля организаций со строгим управлением данными развертывайте версию Enterprise на своей инфраструктуре, чтобы данные никогда не покидали вашу среду.
- Автономные рабочие процессыМодели Tailor Foundation для изучения ваших процессов, позволяющие им автономно выполнять задачи извлечения и генерировать отформатированные результаты.
Основные характеристики
- Высокопроизводительное извлечение из отсканированных PDF-файлов, изображений и текста
- Структурированное извлечение данных для кормления баз данных и баз знаний
- Готовое качество с уменьшенными галлюцинациями
- API-первый доступ для масштабируемой добычи
- Развертывание On-Prem для защиты конфиденциальности
- Настраиваемые базовые модели для конкретных задач (например, медицинское кодирование, индивидуальные рабочие процессы)
- Автономные агенты, способные обучать и выполнять рабочие процессы
- Многоязычные возможности и многоязычные варианты использования
Случаи использования
- Структурированное извлечение для интеграции данных в базы данных и базы знаний
- Доменные задачи, такие как медицинское кодирование и специализированное извлечение информации
- Генерация Markdown и другие задачи форматирования контента, полученные из извлеченных данных
- Автоматизация повторяющихся рабочих процессов извлечения информации с помощью автономных агентов
Безопасность, конфиденциальность и соблюдение
- Опция развертывания On-Prem для обеспечения конфиденциальности данных и контроля
- Настройка корпоративного уровня в соответствии с управлением организационными данными
- Предназначен для уменьшения галлюцинаций и повышения надежности при извлечении критической информации
Предприятие и ресурсы
- Корпоративная платформа и предпосылки для частного развертывания
- Доступ к API и веб-платформе для разработчиков и команд
- Ресурсы включают сообщения в блогах, документацию и каналы сообщества (Discord, GitHub и т. Д.)
Как это работает (технический обзор)
- NuExtract: флагманский LLM, специализирующийся на извлечении структурированных данных из различных форматов документов
- настраиваемые трубопроводы, чтобы определить, какую информацию извлекать и как ее форматировать
- Опции On-Prem и Cloud в соответствии с требованиями конфиденциальности, задержки и соответствия
Безопасность и правовые соображения
- Обеспечение соблюдения политик обработки данных при загрузке документов
- Проверка извлеченных данных перед подачей в нижестоящие системы
Основные понятия Резюме
- Извлеките структурированную информацию из PDF-файлов, изображений, таблиц и текста
- Экстракция на основе API в масштабе с ключом API
- Предварительное развертывание предприятия для обработки частных данных
- Автономные агенты для изучения и выполнения рабочих процессов извлечения
- Специфическая настройка домена для уменьшения галлюцинаций и повышения точности
- Многоязычная поддержка широкого применения