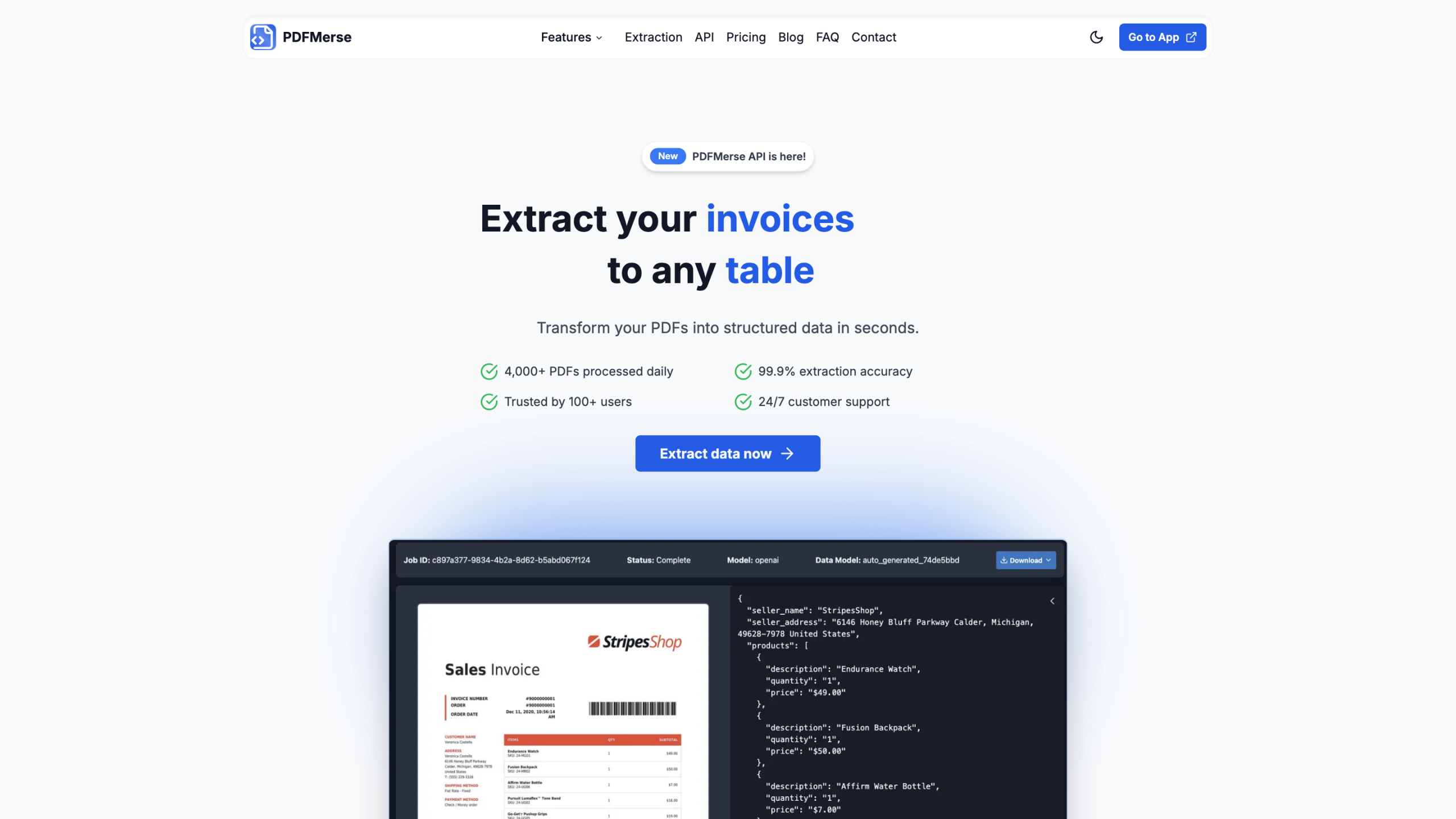
PDFMerse — это PDF-экстрактор данных на базе ИИ, который преобразует любой PDF-файл в структурированные данные за считанные секунды. Он обрабатывает тысячи PDF-файлов ежедневно с высокой точностью и предлагает несколько выходных форматов, доступ к API RESTful и многоязычную поддержку для различных рабочих процессов.
Ключевые способности
- Автоматизированное извлечение данных из различных PDF-файлов (счета-фактуры, медицинские записи, юридические документы и т.д.)
- Гарантированные структурированные данные, готовые к немедленному использованию в ваших системах
- Поддержка нескольких языков и распознавание рукописного текста для более широких типов документов
- Выходные форматы включают JSON, CSV и Excel с планами дополнительных форматов
- Высокопроизводительный API, предназначенный для крупномасштабной обработки PDF
- Безопасность: надежная добыча, предназначенная для корпоративного использования
Как это работает
- Загрузите или отправьте PDF-файлы в PDFMerse. ИИ автоматически идентифицирует поля данных на основе модели и вашего ввода.
- Данные извлекаются и структурированы в определенный формат, готовый к интеграции.
- Восстановите вывод в предпочтительном формате через API или загрузите вручную.
Случаи использования
- Автоматический ввод данных из счетов-фактур, квитанций и заказов на покупку
- Извлечение данных пациента или клинических данных из медицинских записей
- Захват юридических деталей документов и создание доступных для поиска записей
- Интеграция извлеченных данных в базы данных, CRM или аналитические инструменты
Особенности
- Автоматизированное извлечение данных: извлечение на основе ИИ сокращает время ручного ввода.
- Гарантированные структурированные данные: всегда предоставляются в определенной, пригодной для использования структуре.
- Валидация экстракции: встроенные проверки обеспечивают точность и согласованность.
- Автоматизированная модель данных: Опишите, что извлечь, и ИИ автоматически строит модель.
- Многоязычная поддержка: обработка документов на нескольких языках.
- Поддержка рукописного текста: распознает печатный и рукописный текст.
- RESTful API: простая интеграция с простыми HTTP-запросами.
- Структурированный, гарантированный результат: выход JSON с гарантированным форматом для безопасной интеграции приложений.
- Высокая производительность: оптимизирована для скорости и больших объемов.
- Безопасность и надежность: Сосредоточьтесь на точности данных и безопасной обработке.
Как использовать PDFMerse API
- Выберите план: бесплатный, базовый, профессиональный или бизнес на основе объема страницы и потребностей в функциях.
- Используйте API RESTful для отправки PDF-файлов и получения структурированных данных в JSON (или других поддерживаемых форматах).
- Используйте пользовательские модели данных для адаптации извлечения к вашим рабочим процессам.
Планы и цены (резюме)
- Бесплатный: ограниченный доступ, до небольшого количества страниц, выход JSON, поддержка сообщества.
- Базовый: $5/месяц, до 100 страниц/месяц, выход JSON, доступ к API, поддержка сообщества.
- Профессиональный: $29 в месяц, до 1000 страниц в месяц, несколько выходных форматов, расширенное создание модели данных, полный доступ к API (2000 кредитов в месяц).
- Предприятие: $79 в месяц, неограниченные страницы, все форматы вывода + полный доступ к API, поддержка 24/7, выделенный менеджер учетных записей, пользовательские интеграции.
Безопасность и безопасность данных
- Обработка данных предназначена для корпоративного использования с безопасной и надежной обработкой.
FAQ Основные моменты
- Какие PDF-файлы можно обрабатывать? Различные типы, включая отсканированные и нативные PDF-файлы.
- Насколько точна экстракция? Высокая точность с встроенной валидацией.
- Какие форматы вывода поддерживаются? JSON и планы на CSV/Excel (существующие или предстоящие).
- Безопасны ли данные? Да, предназначен для безопасной и надежной добычи.
Начало работы
Быстро извлекайте данные из PDF-файлов с помощью API извлечения на базе AI от PDFMerse и преобразуйте ваши документы в реальные данные.