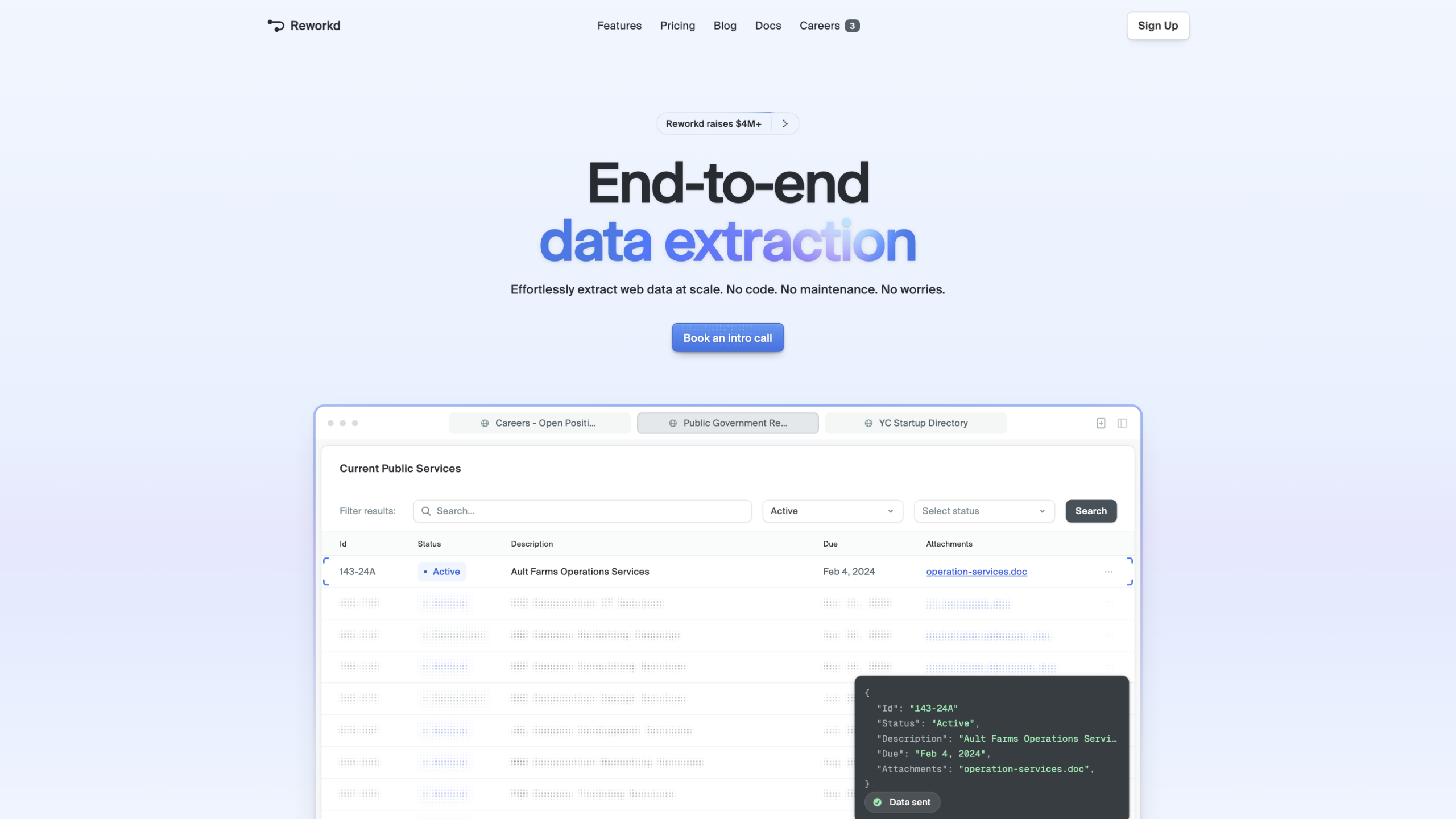
Reworkd / Reworkd AI Web Data Extraction Tool это комплексная платформа для извлечения данных, которая автоматизирует весь конвейер веб-данных — от сканирования и генерации кода до извлечения, проверки и доставки — без необходимости ручного кодирования или обслуживания. Он предназначен для масштабирования на сотнях или тысячах сайтов, обработки динамического контента, профилирования и ограничения скорости, предлагая возможности самовосстановления и подробную аналитику для мониторинга здоровья добычи.
Как это работает
- Сканировать и генерировать кодПереработанный сканирует целевые веб-сайты и автоматически генерирует код извлечения, соответствующий вашим требованиям к данным.
- Run extractors & validateСистема выполняет экстракторы, проверяет результаты и обеспечивает надежность данных.
- Выходные данныеЭкспорт данных в нужных вам форматах, в то время как система обрабатывает запросы, прокси и надежность.
- Самоисцеляющиеся скребкиКогда содержание веб-сайта изменяется, Reworkd обнаруживает изменения и восстанавливает конвейер данных без ручного вмешательства.
Почему выбирают Reworked
- Экономьте время, устраняя рукописные скрипты и инфраструктуру.
- Сокращение затрат, связанных с экспертизой по скрапингу данных и инженерными усилиями.
- Минимизируйте операционные проблемы со встроенным управлением прокси, проблемами безголового браузера и проверками согласованности данных.
- Получите видимость для здоровья экстракции с помощью аналитики и приборных панелей.
Случаи использования
- Масштабный сбор веб-данных на многочисленных сайтах
- Регулярно обновляемые данные, такие как правила, цены, объявления о работе или данные о продукте
- Трубопроводы данных, требующие минимального обслуживания и быстрой итерации
Как использовать переработанный
- Определение целевых сайтов и точек данных.
- Переработанные автогенерирующие экстракторы.
- Запустите извлечения и обзор аналитики для обеспечения качества данных.
- Экспорт данных в ваши системы озера данных или ниже по течению.
Данные и соображения конфиденциальности
- Предназначен для рабочих процессов извлечения бизнес-данных.
- Обеспечить соблюдение условий обслуживания сайта и применимых законов при сборе данных.
Особенности
- Сквозной конвейер извлечения данных (crawl -> генерация кода -> извлечение -> проверка -> вывод)
- Подход без кода / с низким кодом: автоматическое генерирование кода для извлечения
- Самоисцеляющиеся скребки, которые исправляют сбои данных и адаптируются к изменениям сайта
- Автоматическая обработка страниц, динамический контент и ограничения скорости
- Автоматизированные повторы, управление прокси и проблемы безголового браузера обрабатываются
- Панель инструментов интерактивной аналитики для мониторинга успеха, неудач и производительности извлечения
- Многоформатный экспорт данных и интеграция с системами нисходящего потока
- Секция команд с открытыми позициями и карьерными возможностями
- Глубокая аналитика и операционные показатели (успех, запуск, ожидание, неудача)
Безопасность и соблюдение
- Использование в соответствии с условиями сайта и применимым законодательством; мониторинг использования данных и обеспечение защиты конфиденциальности, где это необходимо.
Компания / Контакт
- При поддержке известных учредителей и специалистов, связанных с YC; акцент на автоматизацию и снижение нагрузки на инфраструктуру данных.