Нечеткий матч
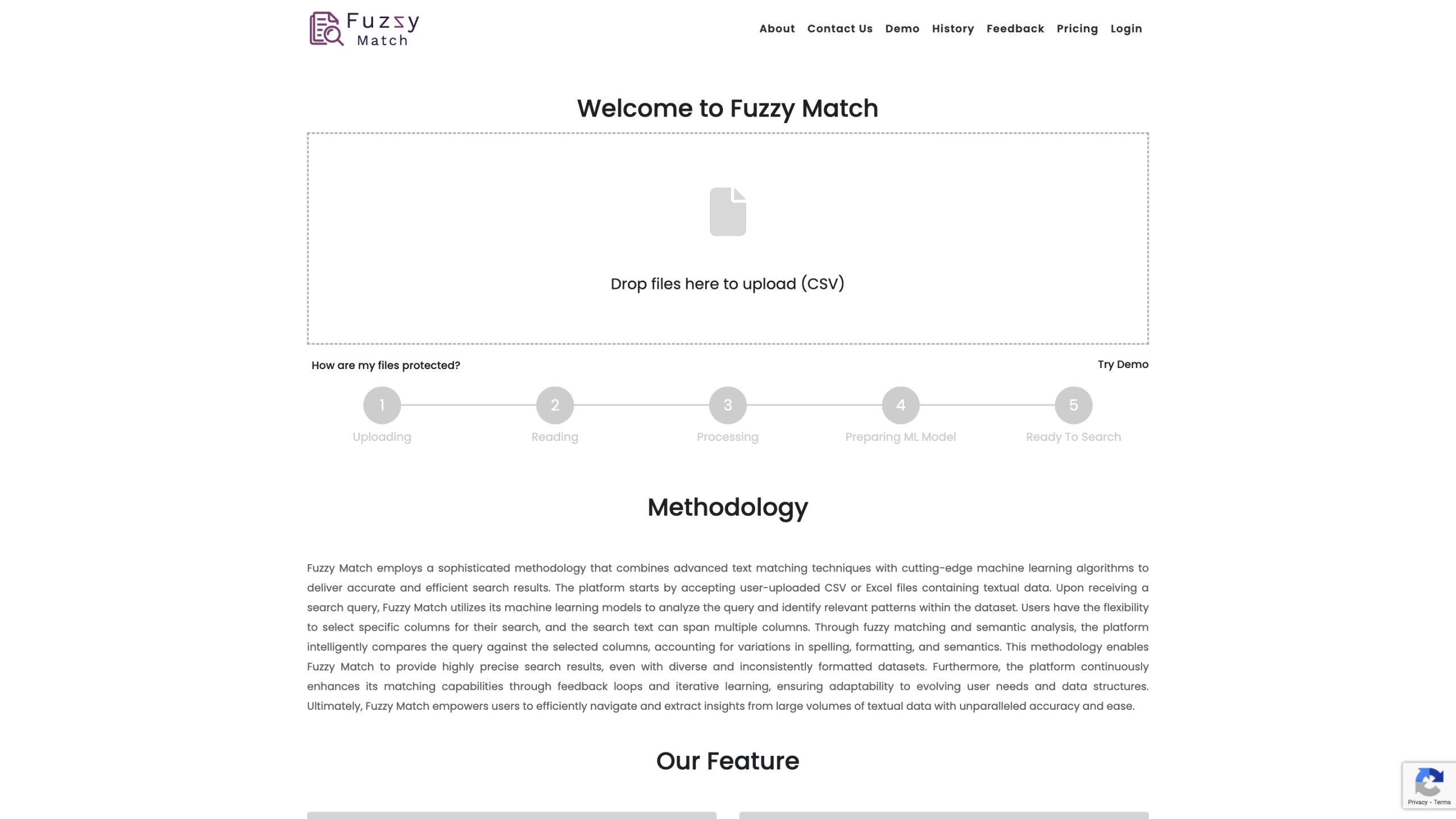
Fuzzy Match — это платформа для сопоставления данных, которая использует передовые методы сопоставления текста и машинное обучение для предоставления точных и эффективных результатов поиска по текстовым данным. Он принимает загруженные пользователем файлы CSV или Excel и позволяет выполнять поиск по одному или нескольким столбцам, приспосабливая опечатки, орфографические ошибки и различные форматы данных посредством семантического анализа и адаптивного обучения.
Как это работает
- Загрузка: Импорт файлов CSV или Excel, содержащих текстовые данные.
- Выберите конкретные столбцы для поиска (текст может охватывать несколько столбцов).
- Запрос: Введите поисковый запрос.
- Матч: Платформа анализирует запрос против выбранных столбцов с помощью нечеткого сопоставления и семантического анализа, перенося орфографические вариации и различия форматирования.
- Обучение и адаптация: непрерывные циклы обратной связи и итеративное обучение со временем улучшают соответствие, адаптируясь к меняющимся структурам данных и потребностям пользователей.
Случаи использования
- Очистка и дедупликация данных в больших наборах текстовых данных
- Поиск соответствующих документов из шумных корпусов
- Улучшения поиска, которые переносят опечатки и изменения формата
- Семантический поиск по неоднородным источникам данных
Защита данных и конфиденциальность
- Загруженные файлы надежно хранятся и автоматически удаляются через 24 часа. Пользователи могут удалить данные из истории.
- Акцент на сохранении конфиденциальности данных во время обработки и хранения.
Как использовать Fuzzy Match
- Загрузите свой файл данных. Поддерживаются форматы CSV или Excel.
- Настройка области поиска. Выберите одну или несколько колонок для включения в поиск.
- Введите свой поисковый запрос. Включите термины или фразы, которые вы хотите найти в наборе данных.
- Проведите поиск. Результаты обзора, которые улучшаются с помощью нечеткого и семантического сопоставления.
- Уточнить по мере необходимости. Используйте петли обратной связи для повышения точности сопоставления в будущем.
Основные характеристики
- Надежное нечеткое соответствие, чтобы терпеть опечатки и орфографические ошибки
- Семантический анализ для повышения точности сопоставления различных данных
- Гибкая область поиска на уровне столбцов в наборах данных CSV / Excel
- Непрерывное обучение с циклами обратной связи для адаптации к изменениям данных
- Высокая производительность на больших, шумных текстовых наборах данных
- Обработка конфиденциальных данных с автоматическим удалением данных через 24 часа
- Четкая передача сообщений о защите данных и контроль пользователя над загруженными файлами